Releases
This release marks another major addition to CloverDX Server functionality. Job Inspector allows support teams to work more efficiently thanks to visual representation of graphs, component settings and more along with execution log, all in one place.
To help users of Data Apps, we added advanced data viewer, allowing sorting and filtering data directly from results screen and many smaller improvements. For example, ability to define default values for any input field which makes use of Data Apps far more comfortable.
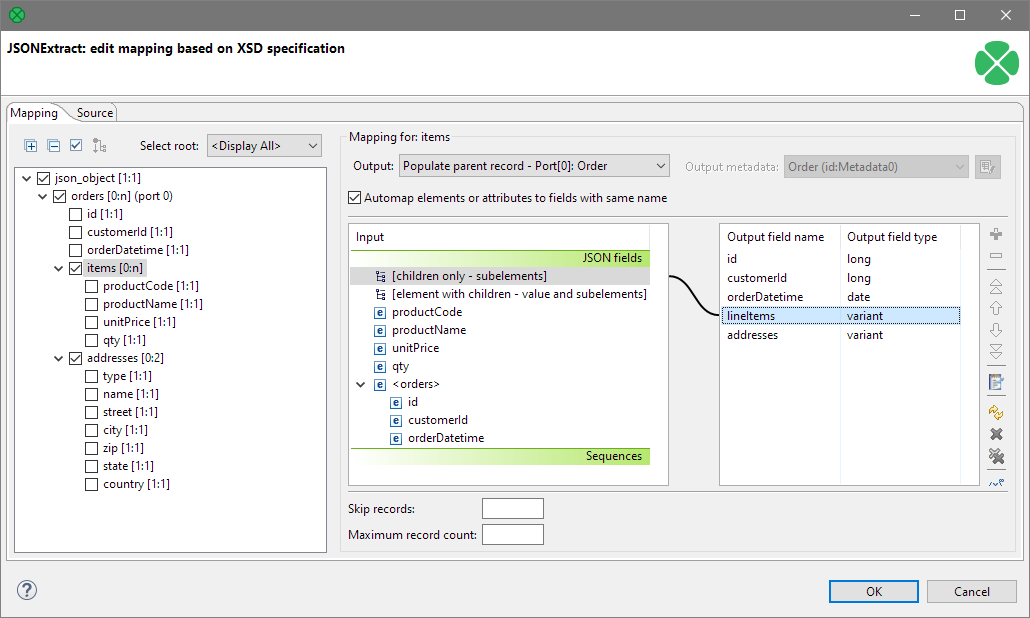
We significantly improved our support for complex semi-structured data (JSON and similar formats). You can now use new variant data type to transport complex data structures, read or write them using JSONExtract and JSONWriter components.
We are continuing our effort to extend our connectivity and data format support. This release introduces new CTL functions allowing you to work with Apache Avro format. Apache Parquet components introduced in previous release received some goodies and now support newer Parquet formats. We also improved our Kafka components which now graduated from Incubation. Azure Blob Storage joined ranks of our remote protocols to help you work with data in the Azure cloud.
More powerful Excel spreadsheet components are frequent asks. We listened to you and added support for reading and writing formulas and hyperlinks as well as many other smaller quality-of-life and performance improvements to our SpreadsheetDataReader and SpreadsheetDataWriter components.
CloverDX Server REST API now includes automation control features. It is now possible to enable and disable Schedulers, Event Listeners and Data Services using new family of endpoints.
And much more...
New features in 5.11
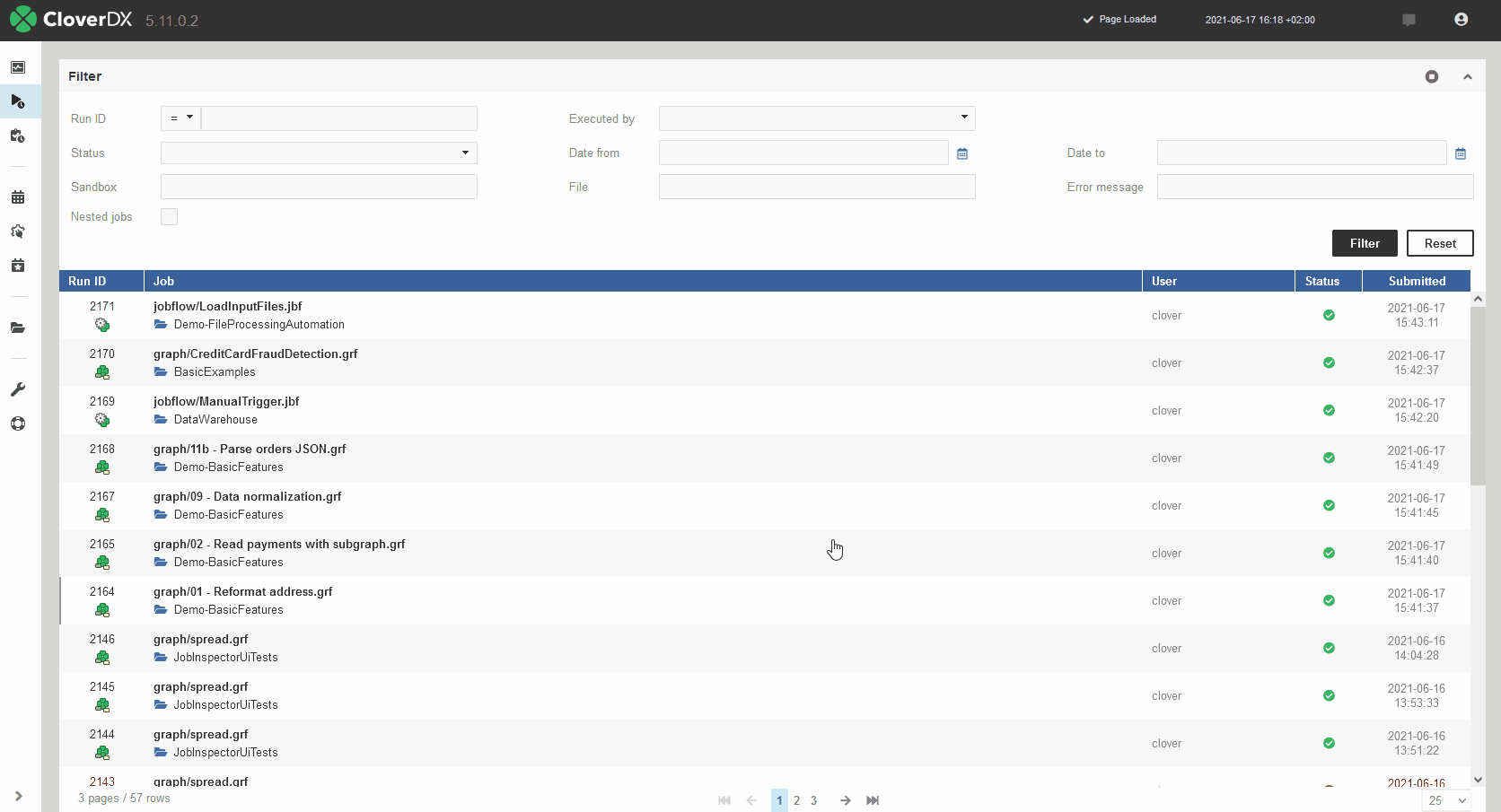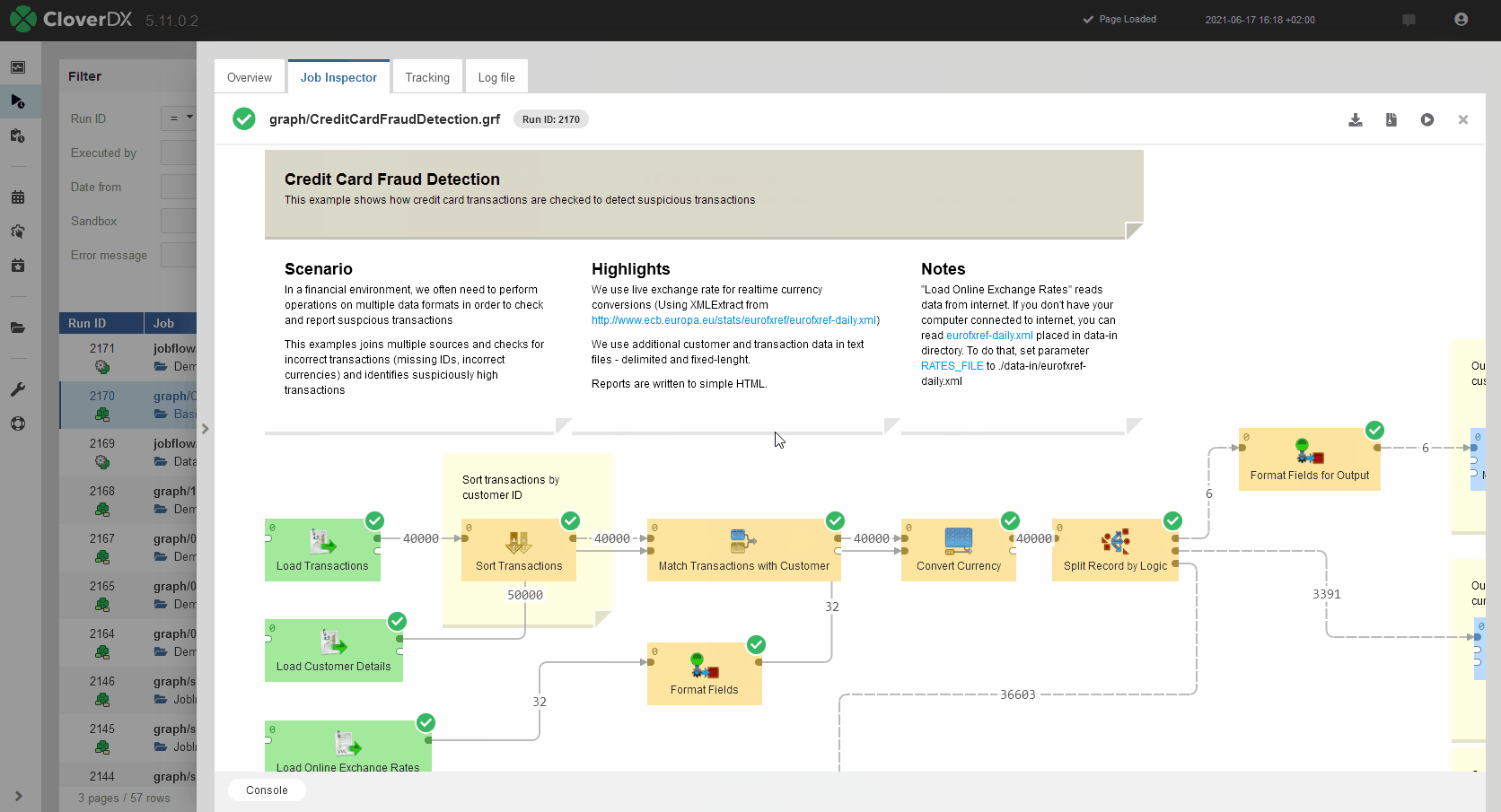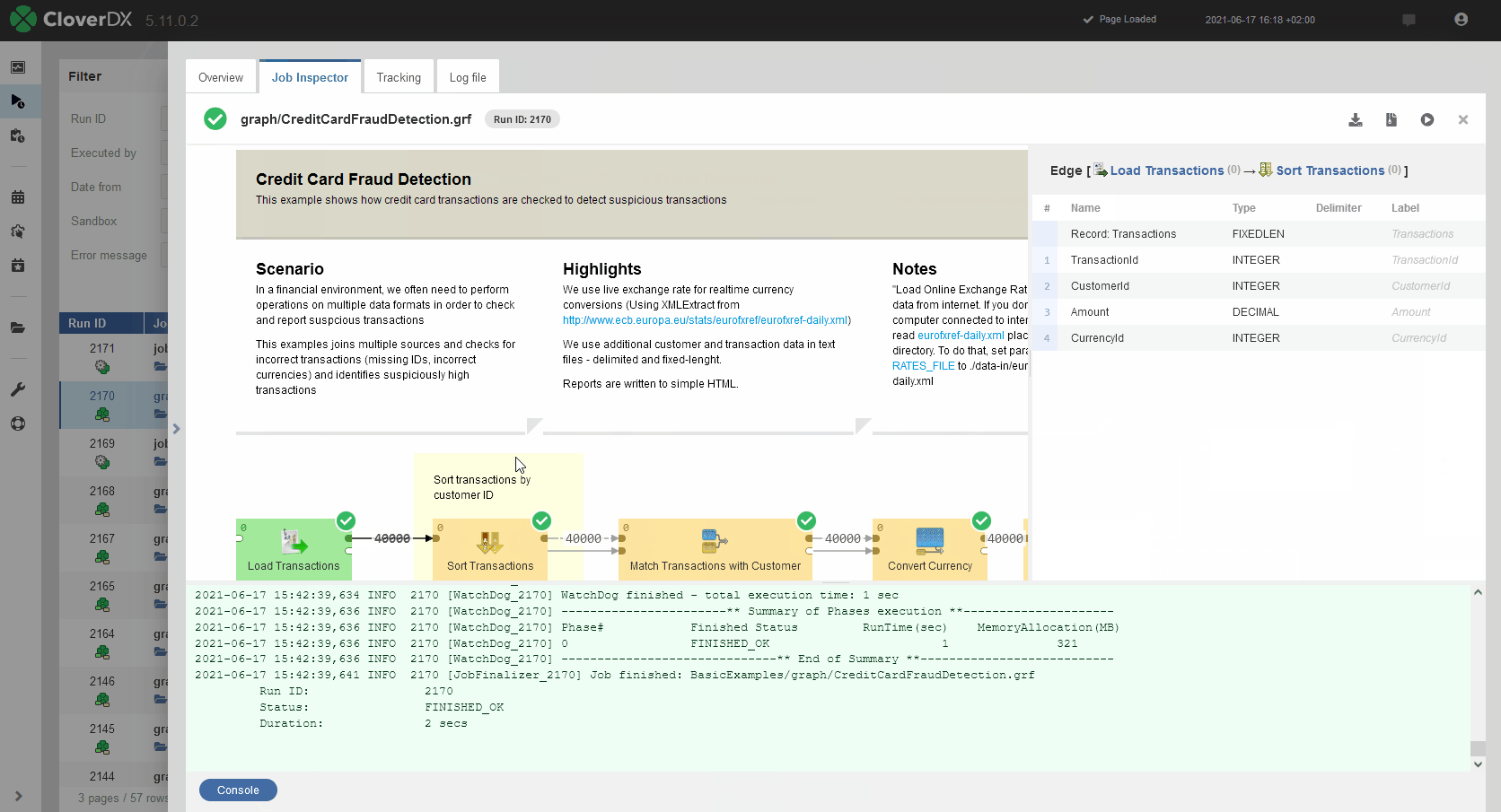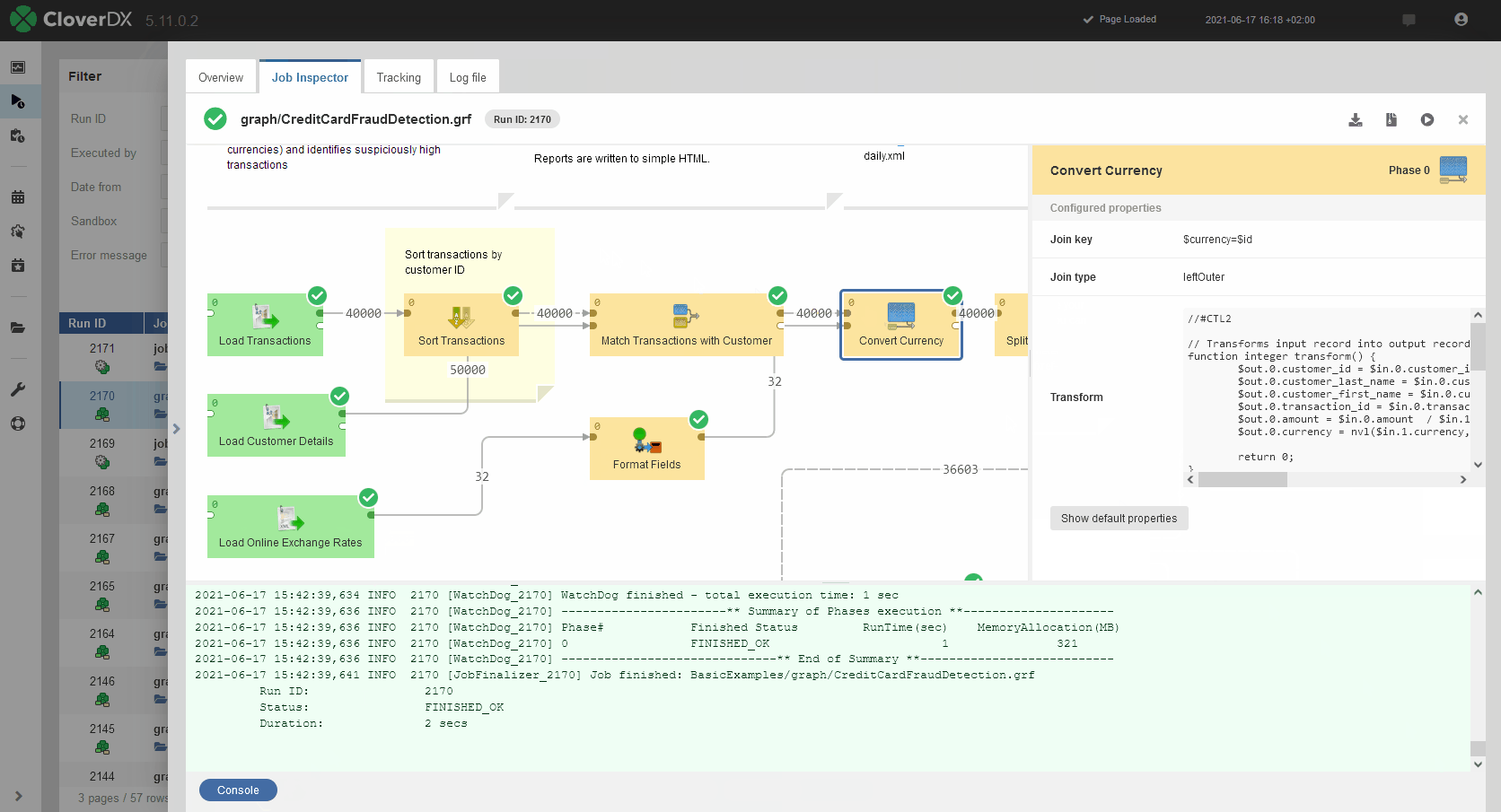
Job Inspector
Job Inspector is a new, integral part of the Server Console that will allow you to view your graphs and other types of jobs like jobflows, subgraphs or even data services directly in server environment without having to open CloverDX Designer.
Job Inspector will help you to quickly review overall data flow, metadata on all edges, job logs, component configuration and more. This makes it ideally suited for issue investigation on production. It does not allow any job editing so even users with limited privileges can use it to view jobs.
When job fails, Job Inspector provides means to efficiently investigate why an error occurred. For running jobs, Job Inspector provides real-time monitoring of job progress.
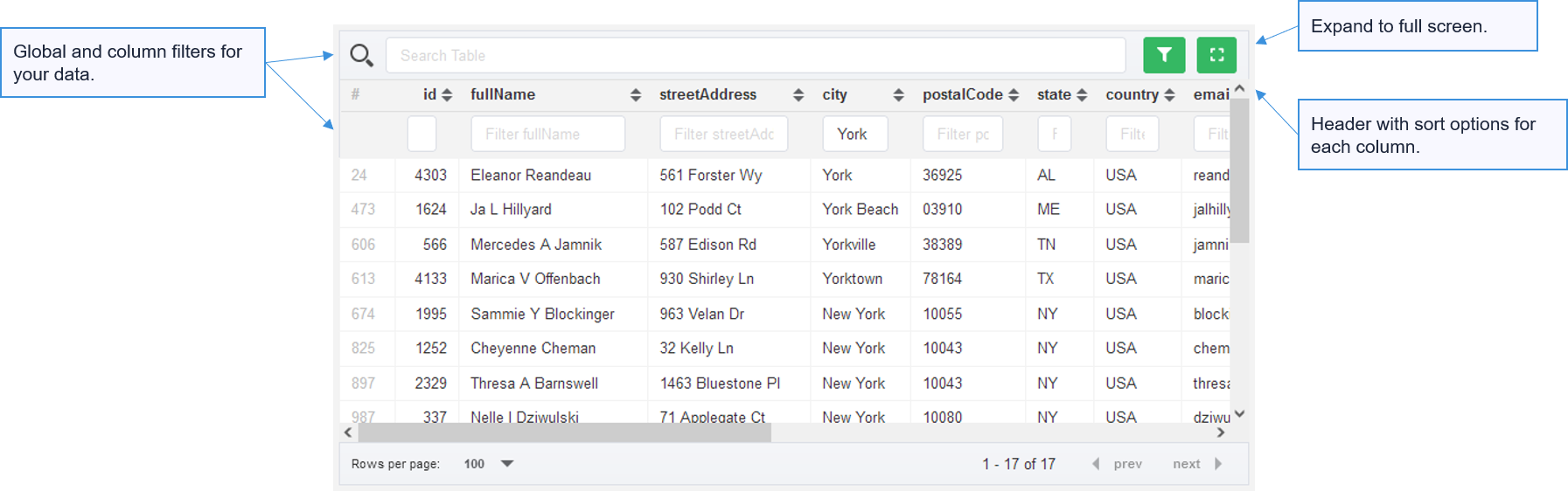
CSV output preview in Data Apps
Data Apps have become one of our core features as many users now use them to run variety of ad-hoc processes in simple and easy user interface.
CloverDX 5.11 extends Data App interface with more powerful data viewer, allowing users to work with results directly in browser. CSV data will now be displayed in rich table view with headers as defined in output metadata. You can sort, search and browse through your data.
Variant and semi-structured data
With our introduction of variant data type in CloverDX 5.6 we allowed engineers to build processes more effectively by native support of semi-structured formats - JSON and BSON.
In this release, we are improving this functionality by adding support for variant fields in metadata. You can now transport variant data throughout your transformations, use it in components without need for conversion to and from variant.
JSONExtract and JSONWriter now natively support variant so you can easily read or write whole (sub)sections of JSON documents into a single metadata field.
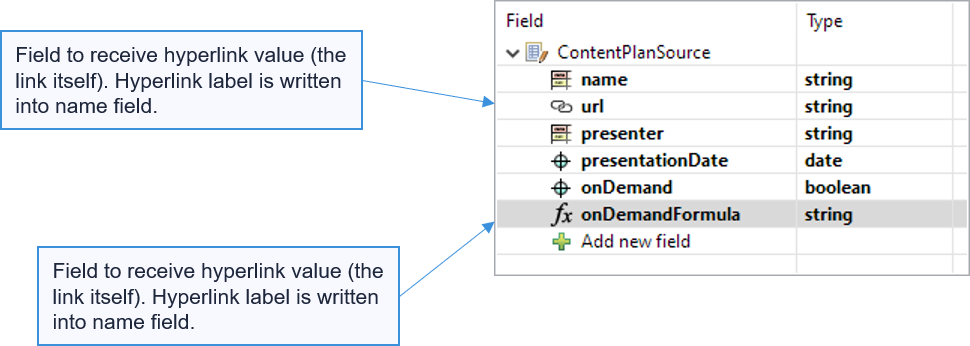
Formulas and hyperlinks in Microsoft Excel files
SpreadsheetDataReader and SpredsheetDataWriter were extended for reading and writing of formulas and hyperlinks. With the improved components you can read and write more complex and more interactive spreadsheets.
We also improved Map by name feature which is commonly used when reading files where headers can appear out of order. Automated mapping is more robust and predictable, thanks to normalization of header data and improved field matching algorithm. It will help you match your columns in wider range of cases regardless of letter case, extraneous whitespaces and use of special characters.
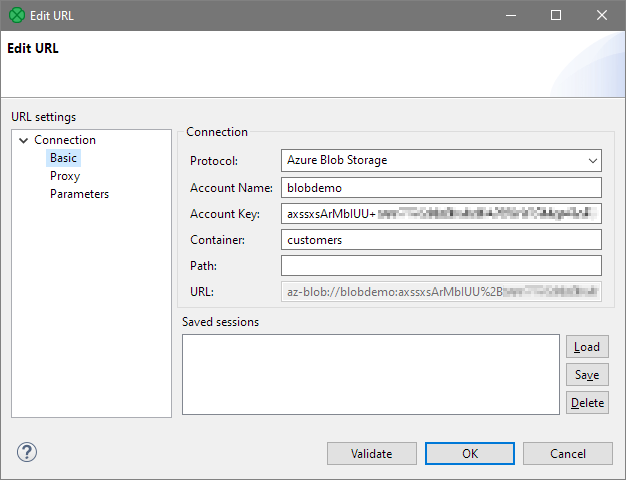
Azure Blob Storage connectivity
To support growing number of CloverDX deployments in Azure cloud, we are introducing new remote protocol - Azure Blob Storage. Azure Blob protocol can be used in all Readers, Writers and File Operations components. This allows you to work with any file type or file format (like csv, json, etc.) or work with files directly (to copy, move, delete, etc.). To access data in Azure Blob, use URL with az-blob:// prefix.
Apache Avro format support (Incubation)
CloverDX 5.11 adds one more data format to help you work with complex, semi-structured data – Apache Avro. We are introducing three new functions that allow you to work with Avro data directly in your transformations:
-
variant parseAvro(byte avroData, string avroSchema)
-
byte writeAvro(variant value, string avroSchema)
-
string getAvroSchema(variant data)
These functions allow you to convert any Avro data to, and from variant. You can then use variant to implement business logic to transform Avro data as needed.
Main use case for these functions is to help you work with messaging use cases that use Avro as the data format. For example, you can now easily connect to Kafka topic, pull Avro messages from it, map incoming data to your internal format and load into your target system.
These functions are now considered to be in Incubation. We will be working on further upgrades to extend these functions. Even though they are in Incubation, they are fully supported and you can safely use them in your production code as needed.
Server REST API
Latest additions to CloverDX Server REST API are methods which allow you to enable or disable automation features - Schedulers, Event Listeners and Data Services.
These API endpoints will help you build more complex automated deployments for your DevOps or DataOps processes.
Platform support
To help you run CloverDX in demanding and business critical applications, CloverDX 5.11 adds support for two deployment stacks – combinations of operating system, application server and Java JDK distribution – all with commercial support by their vendors.
To ensure the stability of the deployment, these stacks are supported as single configurations and should not be mixed with open-source alternatives or between each other.
Red Hat stack
This stack is built on top of Red Hat technology:
- Red Hat Enterprise Linux 8
- Red Hat OpenJDK 11
- Red Hat JBoss Web Server 5.4
VMware (Pivotal) stack
VMware stack uses VMware (formerly Pivotal) application server and JDK:
- VMware tc Server 4.1
- VMware-supported OpenJDK 11 (BellSoft Liberica JDK 11)
We test VMware stack on CentOS and on Ubuntu Linux. We are still supporting existing tc Server 3.1 deployments even though tc Server 3.1 is no longer officially supported.
Compatibility notice
JBoss EAP 7.1 support
CloverDX 5.11 is the last CloverDX release that will support JBoss EAP 7.1 as target application server. CloverDX releases starting with CloverDX 5.12 (planned in September 2021) will only support JBoss EAP 7.2 deployments. We advise customers running CloverDX on JBoss EAP 7.1 to upgrade to JBoss EAP 7.2.
To help you install or upgrade to this version, we've prepared a simple checklist:
Before You Upgrade
- Be sure to check the "Compatibility" notes for ALL intermediary releases. We mark all changes that can potentially alter the function of your existing transformations with a "Compatibility" label. Typically, you can safely ignore most of them, as we try hard to keep as much backwards compatibility as possible. There's a comprehensive list of all releases that will help you get the information quickly.
- Upgrade Designer and Server together. We always release Designer and Server together under a single version. It's highly recommended to upgrade Server and all Designers at the same time. Although using different versions of Designer to connect to Server might work, it is not generally supported.
- There are no incremental patches. We don't release incremental patches. Every upgrade is in fact a full installation that, if installed over the older version, will automatically update whatever is necessary in your workspaces, sandboxes, and Server databases as needed, no user data will get overwritten.
- Don't forget to backup. Although none of the above upgrade steps requires explicit backup, we recommend you always back up your work. The upgrade will keep all your transformations, jobflows, and configurations safe. However, as a good word of advice, it never hurts to have a backup.
Designer Upgrade
- Download the latest version by logging into your customer account. If you lost your credentials or no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Install the new version of Designer. You can install Designer over your existing installation. The process will automatically clean up the old version. Don't worry, you will NOT lose your workspaces, graphs, and transformations. However, if you installed some additional plugins to Designer (Eclipse plugins) you might need to reinstall them. Eclipse should automatically help you do that. When you start the application, point it to your existing workspace directory. With some major releases, we may notify you about upgrading the workspace to the latest version. In such cases, you won't be able to use the workspace with previous versions—be sure to upgrade ALL Designers at once if you're sharing the workspace.
- Activate the product on first start. You will need a new key as we issue new license keys for every new major version (e.g. from 4.9 to 5.0). If you're on our maintenance program, we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license keys from there. If you can't find the latest keys, please contact us to renew your product maintenance.
Server Upgrade
- Download the latest version by logging into your customer account. You'll find Server in the same list as Designer downloads. If you no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Plan for downtime. Upgrading Server requires downtime, so plan your upgrades in advance. If you're running multiple environments, upgrade the non-production installation first and run all your tests there first.
- Follow our step-by-step Server Upgrade Guide. We've prepared detailed instructions on how to properly shut down Server and install a new one. Server will upgrade its database and sandboxes from any previous version automatically.
- Activate the product on the login screen of Server Console. Server requires new license keys with every major version (e.g. from 4.9 to 5.0) and we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license key from there.
| Release | Compatibility/Upgrade notes, Features & Fixes | Published | Download | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| April 14, 2022 | Documentation Download CloverDX 5.11 5.11.5 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
February 22, 2022 | Documentation Download CloverDX 5.11 5.11.4 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
December 21, 2021 | Documentation Download CloverDX 5.11 5.11.3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| November 09, 2021 | Documentation Download CloverDX 5.11 5.11.2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
List Files Streaming
Fixes
Platform Updates & Security
|
August 10, 2021 | Documentation Download CloverDX 5.11 5.11.1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Job Inspector
Variant Support
Azure Blob Storage
Spreadsheet Components
Data Apps
Kafka
Parquet
Avro
REST API
Oracle Database
IBM MDM
Deployment Stacks
Mics
Security Fixes
Fixes
Compatibility
|
June 23, 2021 | Documentation Download CloverDX 5.11 5.11.0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- For Developers (Improvements most useful for developers bringing new functionality or optimizations in data transformation and orchestration)
- For Administrators (Improvements or features that will help setup, install, administer and manage the platform)
- For Support (Helps staff supporting the production environment to identify and escalate potential problems or avoid such)
- For Security (Improvements and changes relevant to security focused staff – sys admins and developers alike)