Releases
CloverDX 6.2 marks another major update to the CloverDX platform with regards to usability for business users (domain experts). In this release, we focused on connectivity and collaboration between domain experts and IT team to allow organizations to work with their data more effectively.
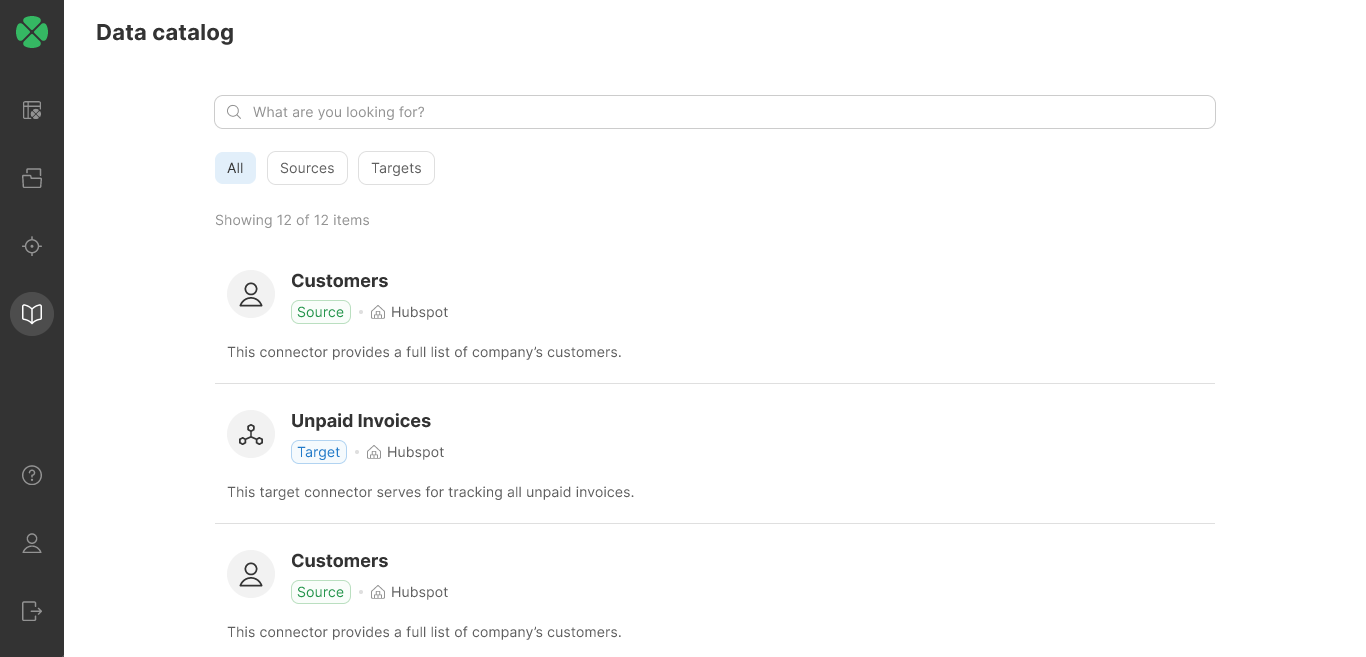
We’ve added support for Data targets which allow Wrangler users to write their data to any system instead of just CSV or Excel files. Data targets are managed in Data Catalog just like Data sources allowing domain experts to quickly see all the data they can work with – whether on the input or on the output side.
Data targets also make it possible for Wrangler users to build data mappings in Wrangler’s simple interface and then share the resulting mapping with the IT team. IT can then bundle the Wrangler-created mappings as part of a larger process thus allowing Wrangler users to directly collaborate and contribute to larger solutions for data processing.
CloverDX 6.2 adds five more validation steps in Wrangler to make it easier to verify that your data matches expectations to ensure that only valid records are processed. The new Split column step allows users to easily split data into multiple columns without using complex formulas.
We’ve added support for running CloverDX on Java 17. Java 17 is a newer LTS (Long Term Supported) release of Java with support at least until 2027 (compared to Java 11’s support until 2024). At the same time, Java 17 allowed us to increase performance in many cases as well as enable Job queue in Docker for increased stability when running under heavy load.
New features in 6.2
Write to any target in Wrangler
With CloverDX 6.2 we are introducing another major functionality update – CloverDX Wrangler can now write to any target system. You can create Data targets and publish them in the Data Catalog.
Once a target is available in the Data Catalog, you can write to it from your Wrangler jobs instead of the default CSV or Excel targets.
Data targets work just like Data sources. They are built in CloverDX Designer so that you can create targets that implement connectivity to any system – whether it is a cloud application like Salesforce, on-prem or cloud database, or even an API.
To make it easier for you to run your jobs in Wrangler while making sure you do not push incomplete data to your target system, we’ve added Test run functionality. Writing to target is disabled during the Test run so you can focus on getting your data right before enabling the writes to populate your target system.
Visual data mapping in Wrangler
Data targets can request data to match a certain structure by prescribing a set of required or optional columns. When using such a target in your Wrangler job, you will have access to a new Mapping mode which allows you to easily map your data to the layout your target requires.
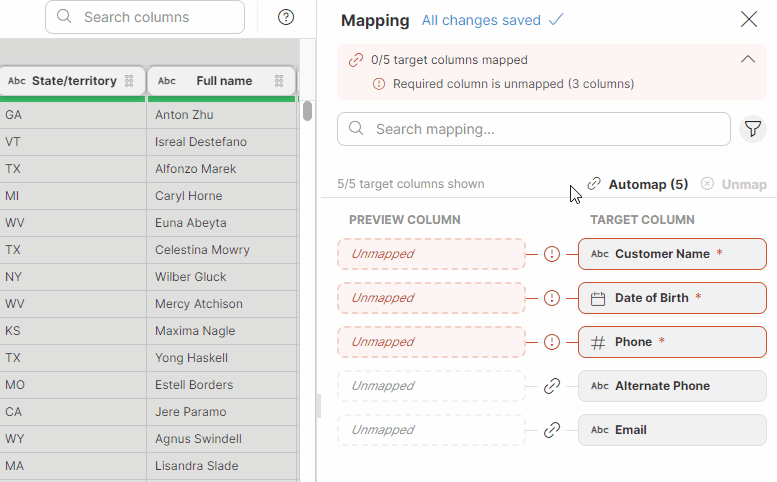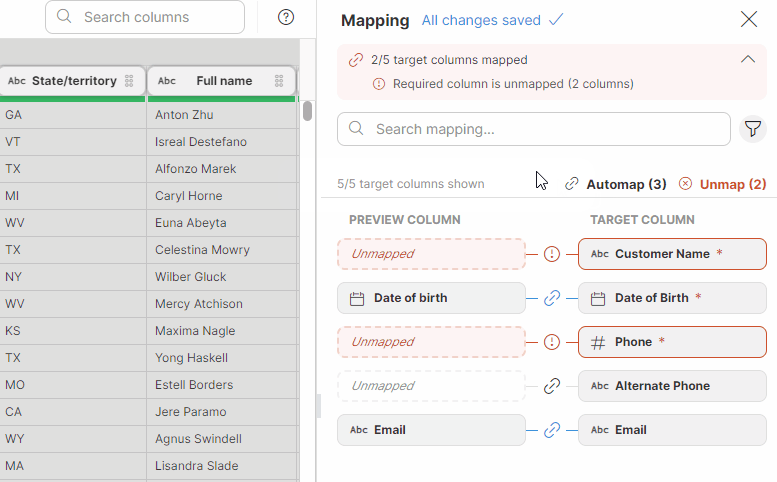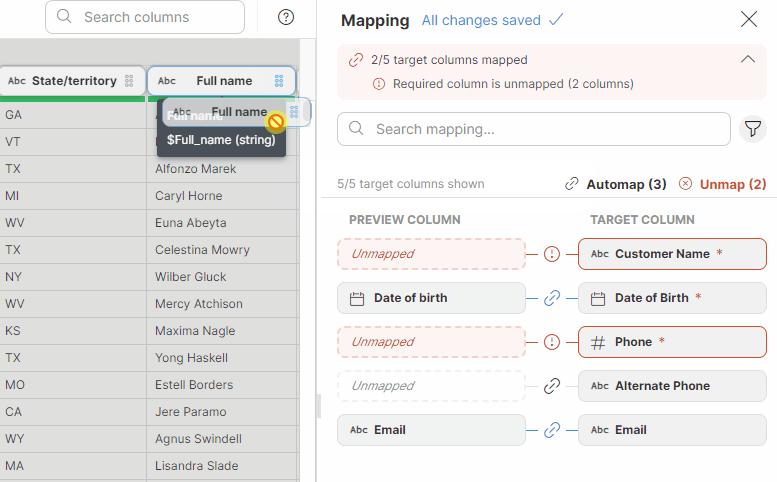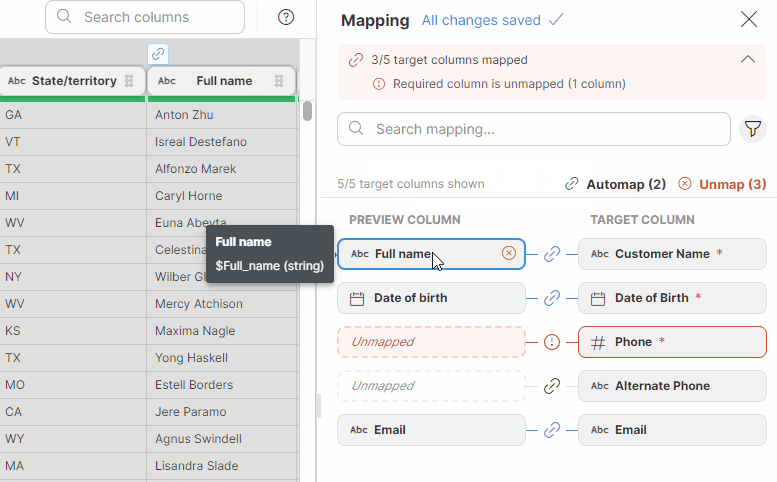
Mapping is interactive and validated as you are working on it. This means you are getting immediate feedback about whether your mapping is complete and whether all required columns are mapped or not. At the same time, mapping does not use any code – it is configured using drag & drop which makes it easy to use.
To make mapping of large number of columns easy, we offer an Auto-mapping functionality. Auto-mapping can suggest column mapping automatically leaving only subset of columns for manual mapping.
Collaboration between business and IT
In CloverDX 6.2 we’ve extended the ability to export your Wrangler jobs and import them into your Designer projects. Jobs imported in this way appear as subgraphs in Designer project. These subgraphs can then be used as any other subgraph as part of a more complex process.
A typical use cases for this are data ingestion or customer data onboarding. In both cases you often need to ingest data in many different formats (for example, from different clients). Building ingestion jobs to read all input formats in Designer can be very time consuming and require a lot of effort from the IT team.
A better solution is to use CloverDX Wrangler in which domain experts create mappings from the source data layouts – they know the data well and can often do this faster than IT-led implementation. Once their Wrangler mappings are ready, they can be exported and shared with the IT team who can integrate them into a larger framework built in Designer.
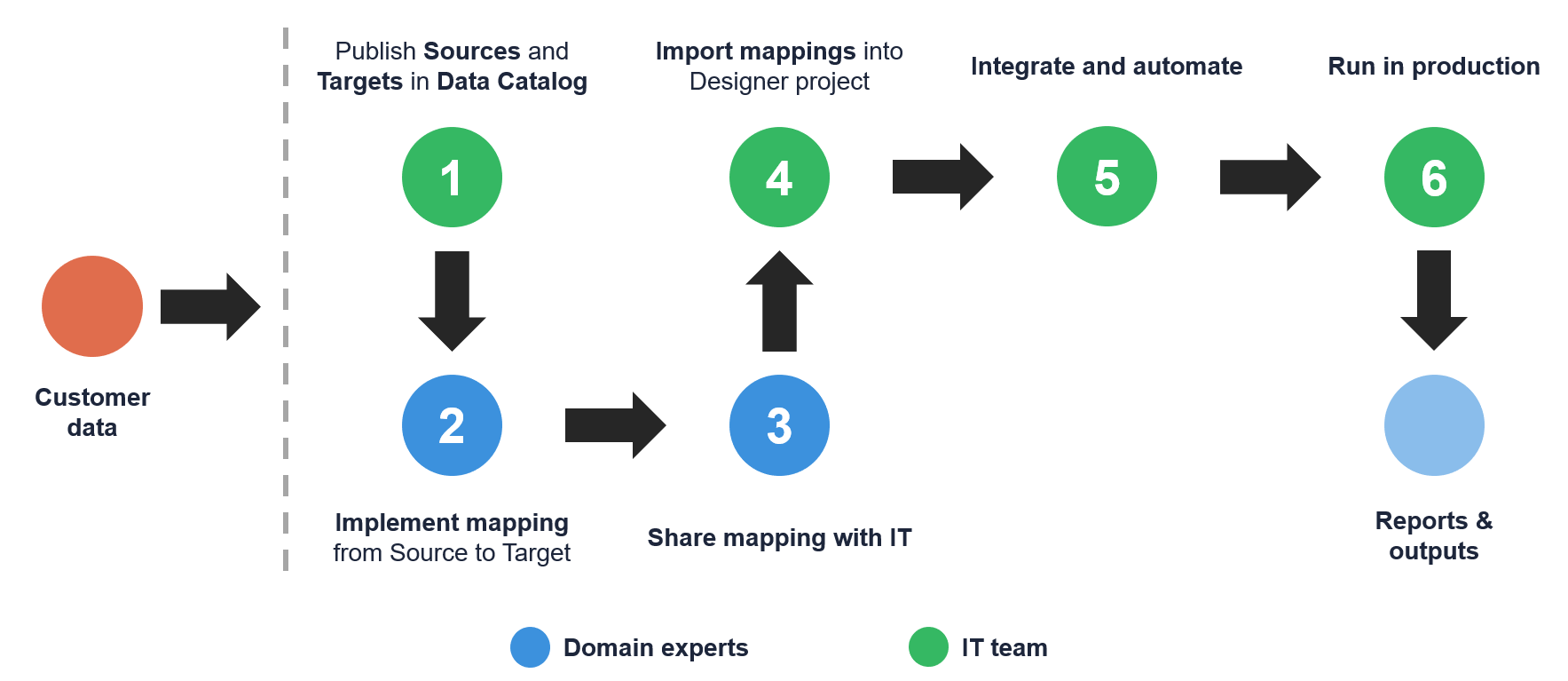
In this way, it is possible for non-technical domain experts to directly design transformations that are part of a larger process that is implemented in Designer and automated on a Server. This can save significant amount of time during processes such customer onboarding.
New Wrangler steps
We are continuing to expand the functionality that allows you to manipulate your data in CloverDX Wrangler. In this release we added several new steps:
- Five new validation steps to make it easier to verify that your data matches your expectations: Validate if not empty, Validate value range, Validate pattern match, Validate text length, and Validate against list.
- Split column step that allows you to split a single column into multiple columns based on a delimiter.
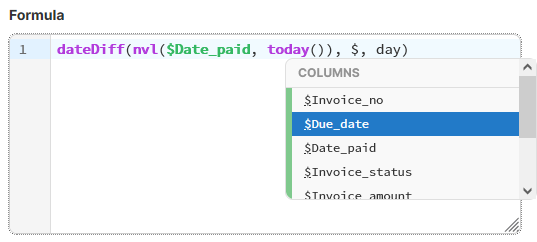
At the same time, we’ve improved usability of many other Wrangler steps. In particular, we’ve added support for content assist and real-time validation of formula into all formula steps (Calculate formula, Filter rows based on formula, Validate with formula).
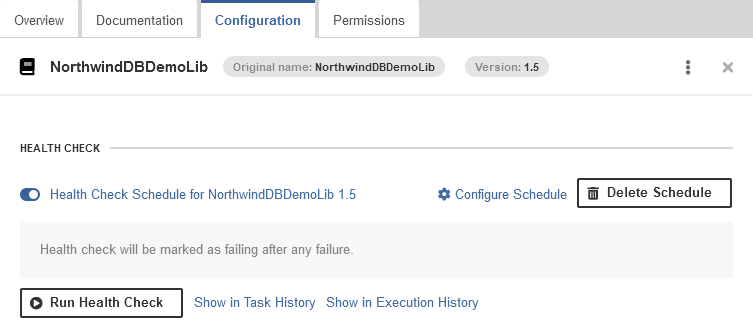
Health check for CloverDX libraries
CloverDX libraries can now designate a special Health Check job in their configuration. The health check job is used by the CloverDX Server to verify connectivity and status of the library – the Server runs the job periodically and depending on its status can mark the library “unhealthy”.
The job can be used, for example, for testing whether APIs that the library needs to work are still accessible etc. It is possible to create Monitors in Operations Dashboard to track the status of library health. In this way you can easily monitor the overall health of the connectors that are deployed on your CloverDX Server instance.
CloverDX on Java 17
We are continuing updates of CloverDX stack and with CloverDX 6.2 you can now run CloverDX Server on Eclipse Temurin JDK 17 when using Apache Tomcat 9 application server.
Java 17 is an LTS (Long Term Support) version with Eclipse Foundation providing support at least until October 2027 compared to Java 11 with support ending in October 2024.
At the same time, you can expect better performance when running CloverDX Server on Java 17. Based on our tests, you should see lower overall memory consumption and 5% to 20% improvements in processing time depending on the use case.
We’ve updated our Docker configuration so that it will now use Java 17 by default. This has one huge benefit – Java 17 properly reports performance metrics when running inside the container which allows us to enable the Job queue by default. This will increase the overall stability of CloverDX Server, especially under heavy load.
Smaller updates
Snowflake driver update
We’ve updated bundled Snowflake driver to the latest version. This update allows us to use a newer and simpler layout for JDBC URL when creating Snowflake connections.
SMB (Samba) access change
We’ve updated the smbj library which provides SMB connectivity in CloverDX. The new version introduces stricter controls for anonymous and guest user access to comply with SMB specification. These changes mean that it is no longer possible to use anonymous access to log-in to SMB. As a workaround, SMB administrators can create user “guest” without a password.
Support package and logs
We’ve added the ability for Server Console users to download support packages from all nodes of a cluster with a single click. This can save a lot of time when working on larger cluster deployments.
Additionally, it is now also possible to download logs for complete execution tree from Executions History in Server Console. Again, this can help when solving issues when running more complex job hierarchies.
New REST APIs
We’ve introduced several new API endpoints:
- To abort a running job: /executions/abort and /executions/{runId}/abort
- To download a support package from a single Server node: /server/support-package
- To download a combined support package from all currently connected cluster nodes: /cluster/support-package
To help you install or upgrade to this version, we've prepared a simple checklist:
Before You Upgrade
- Be sure to check the "Compatibility" notes for ALL intermediary releases. We mark all changes that can potentially alter the function of your existing transformations with a "Compatibility" label. Typically, you can safely ignore most of them, as we try hard to keep as much backwards compatibility as possible. There's a comprehensive list of all releases that will help you get the information quickly.
- Upgrade Designer and Server together. We always release Designer and Server together under a single version. It's highly recommended to upgrade Server and all Designers at the same time. Although using different versions of Designer to connect to Server might work, it is not generally supported.
- There are no incremental patches. We don't release incremental patches. Every upgrade is in fact a full installation that, if installed over the older version, will automatically update whatever is necessary in your workspaces, sandboxes, and Server databases as needed, no user data will get overwritten.
- Don't forget to backup. Although none of the above upgrade steps requires explicit backup, we recommend you always back up your work. The upgrade will keep all your transformations, jobflows, and configurations safe. However, as a good word of advice, it never hurts to have a backup.
Designer Upgrade
- Download the latest version by logging into your customer account. If you lost your credentials or no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Install the new version of Designer. You can install Designer over your existing installation. The process will automatically clean up the old version. Don't worry, you will NOT lose your workspaces, graphs, and transformations. However, if you installed some additional plugins to Designer (Eclipse plugins) you might need to reinstall them. Eclipse should automatically help you do that. When you start the application, point it to your existing workspace directory. With some major releases, we may notify you about upgrading the workspace to the latest version. In such cases, you won't be able to use the workspace with previous versions—be sure to upgrade ALL Designers at once if you're sharing the workspace.
- Activate the product on first start. You will need a new key as we issue new license keys for every new major version (e.g. from 4.9 to 5.0). If you're on our maintenance program, we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license keys from there. If you can't find the latest keys, please contact us to renew your product maintenance.
Server Upgrade
- Download the latest version by logging into your customer account. You'll find Server in the same list as Designer downloads. If you no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Plan for downtime. Upgrading Server requires downtime, so plan your upgrades in advance. If you're running multiple environments, upgrade the non-production installation first and run all your tests there first.
- Follow our step-by-step Server Upgrade Guide. We've prepared detailed instructions on how to properly shut down Server and install a new one. Server will upgrade its database and sandboxes from any previous version automatically.
- Activate the product on the login screen of Server Console. Server requires new license keys with every major version (e.g. from 4.9 to 5.0) and we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license key from there.
| Release | Compatibility/Upgrade notes, Features & Fixes | Published | Download | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
August 01, 2024 | Documentation Download CloverDX 6.2 6.2.2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| November 07, 2023 | Documentation Download CloverDX 6.2 6.2.1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Data Targets in Wrangler
Mapping in Wrangler
New Steps in Wrangler
Wrangler Improvements
Libraries
Java 17
Snowflake
REST API
Miscellaneous
Fixes
Security
Compatibility
|
October 03, 2023 | Documentation Download CloverDX 6.2 6.2.0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- For Developers (Improvements most useful for developers bringing new functionality or optimizations in data transformation and orchestration)
- For Administrators (Improvements or features that will help setup, install, administer and manage the platform)
- For Support (Helps staff supporting the production environment to identify and escalate potential problems or avoid such)
- For Security (Improvements and changes relevant to security focused staff – sys admins and developers alike)