Releases
With this release we are introducing AI and machine learning functionality to CloverDX – you can now run machine learning models locally or use our new OpenAIClient component to interact with LLMs provided by OpenAI.
Our new machine learning components will allow you to use your own models and run inference as part of your data processes. These components focus on data classification using a variety of model types. All run locally without requiring additional accounts or connectivity.
To get machine learning models for these components you can install several new libraries from our CloverDX Marketplace. These libraries contain models packaged for use with CloverDX Server to help you get started quickly.
To help you run your AI and ML workloads effectively, we are also publishing new Docker Hub image designed to run GPU-accelerated machine learning workloads on machines with NVIDIA GPUs and all software dependencies.
Besides the new AI and ML functionality, we’ve made significant improvements to the Data Manager. You can now configure one instance of Data Manager as the “main” instance and have multiple Servers connect to it. This way you can centralize your transactional and reference data set in one place for more effective data governance.
We’ve improved Data Catalog and Wrangler to allow you to directly use reference data sets in Wrangler jobs. Data Catalog now shows reference data set sources and targets so that you can easily use reference data sets as lookups or even add new data to them from Wrangler jobs.
In this release, we are removing support for IBM DB2 as a system database for CloverDX Server. The connectivity to the DB2 from your graphs remains unchanged. See more details in the Platform support section below.
New features in 7.1
Machine learning and AI in CloverDX
We are introducing a set of four new components which will help you work with machine learning models – AITextClassifier, AITokenClassifier, AIZeroShotClassifier and AIAnonymizer.
The first three components allow you to run various data classification machine learning models locally on your own hardware – on CloverDX Server as well as in Designer. Each runs a different type of machine learning model to help you implement different kinds of use cases.

To use these components, you can either download machine learning models from our CloverDX Marketplace and install them on your CloverDX Server / Designer or you can even use your own models after converting them to TorchScript format.
When using these components on your Server, you can use a new AI / ML module in Server console to see what models are available in your environment. You can install new ones in the Libraries module by grabbing them from our Marketplace or by providing your own libraries with AI models.
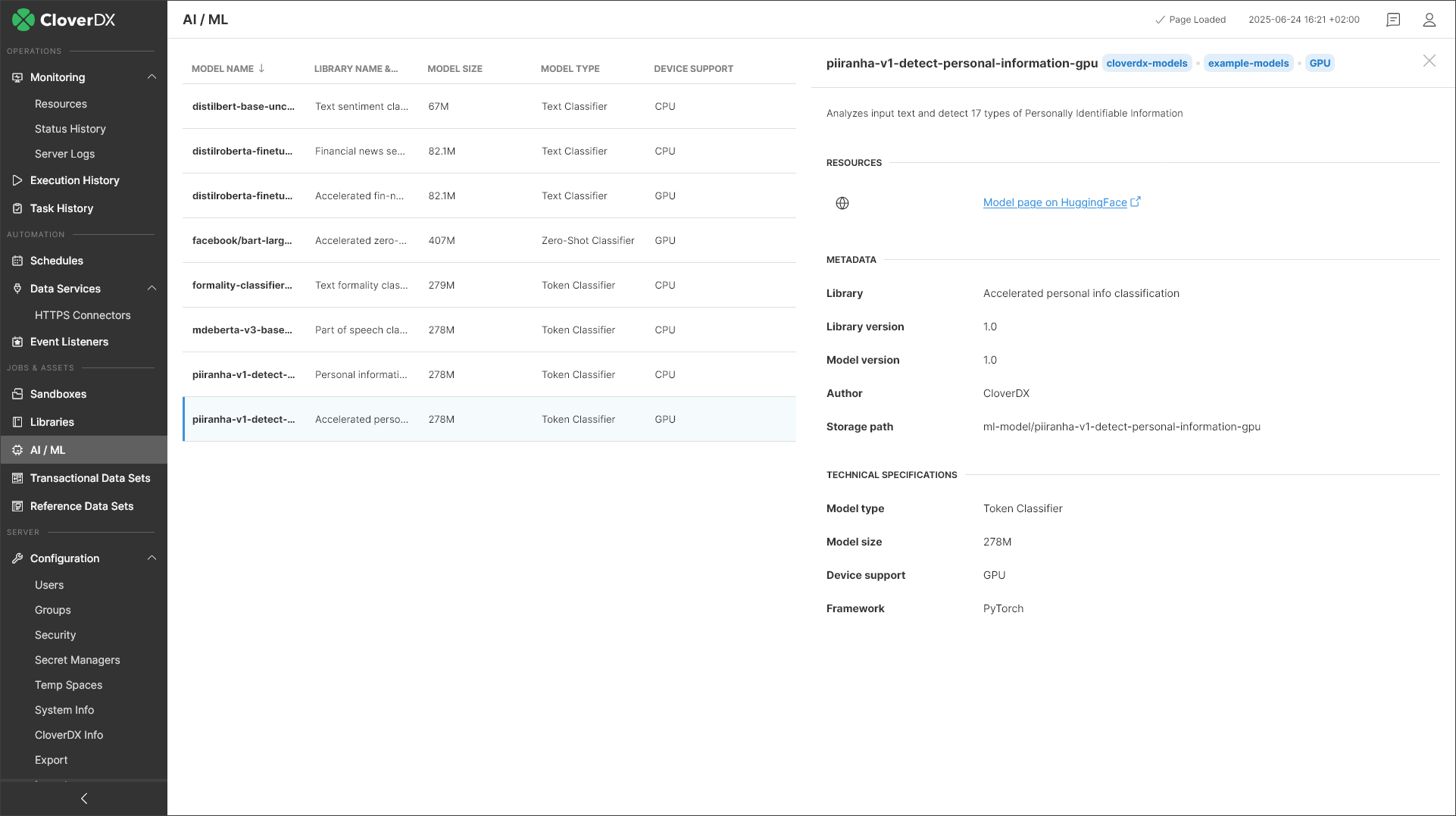
The last component – AIAnonymizer – is a combination of token classifier (same type of model you can run in AITokenClassifier component) and data masking algorithm that uses the model output to mask data flagged by the model. This can be very effectively used for e.g. personal data redaction.
Note that these components are all considered Incubation and their interface may change in future versions of CloverDX.
OpenAIClient component
The new OpenAIClient component allows you to use large language models published by OpenAI in your graphs.
The component connects to OpenAI API and allows you to send your data together with your custom prompt to the API. It will then process the response from the LLM giving you full control over the flow of the “conversation” with the API. This can be used to implement various strategies for response processing and error handling (e.g., asking LLM to regenerate response if the response does not match the expected format and more).
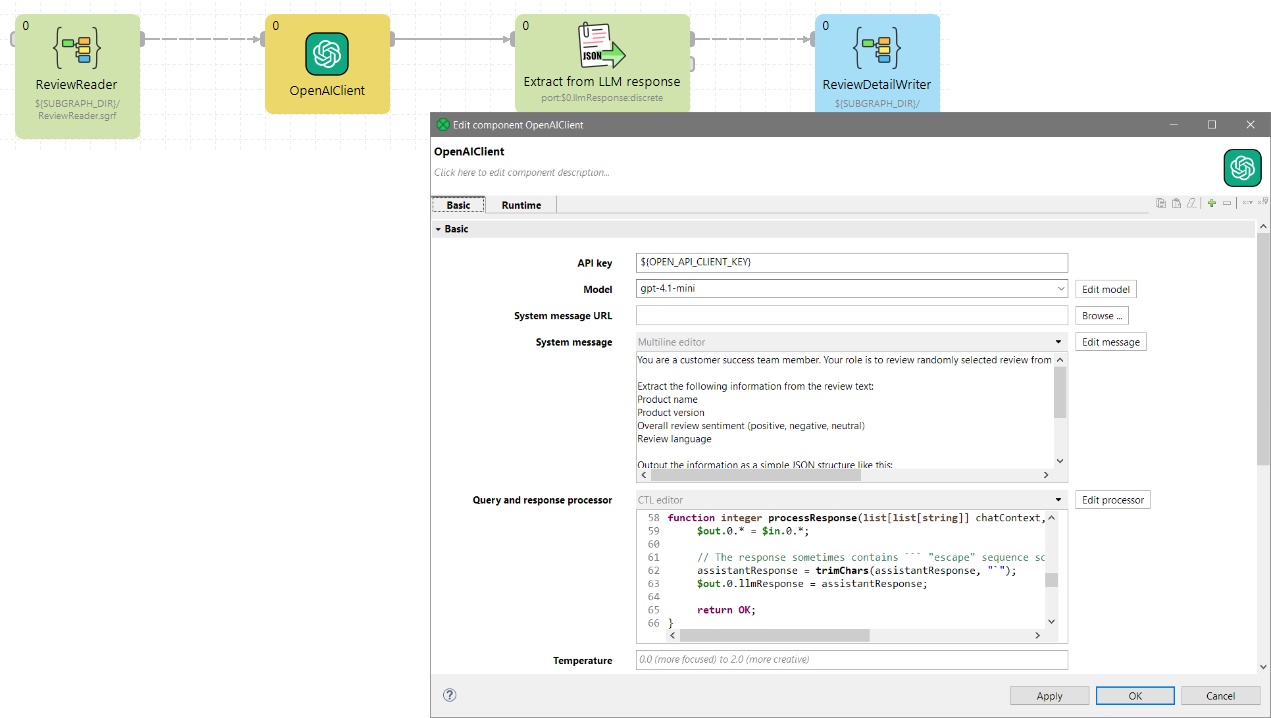
This component is currently considered an Incubation feature.
New AI image on DockerHub
To make it easier for you to work with accelerated machine learning models we are publishing a new Docker image on DockerHub – CloverDX AI image.
This image is preconfigured to allow you to run your machine learning inference via CloverDX components with GPU acceleration providing for significantly higher performance compared to CPU-only execution.
The image can be deployed on any machine where all software and hardware requirements are met. The machine requires NVIDIA GPU with properly configured drivers, CUDA, container toolkit and more.
The easiest way to use this image is to run it on AWS in AWS Deep Learning Base GPU AMI (Ubuntu 24.04) which runs on AWS EC2 G4dn or AWS EC2 G5 instances.
Machine learning models in CloverDX libraries and Marketplace
To use the new AI components, you must install machine learning models in your CloverDX. To make this process as simple as possible, we’ve extended CloverDX libraries to also allow you to store and publish machine learning models.
Several new libraries with machine learning models are available in CloverDX Marketplace.
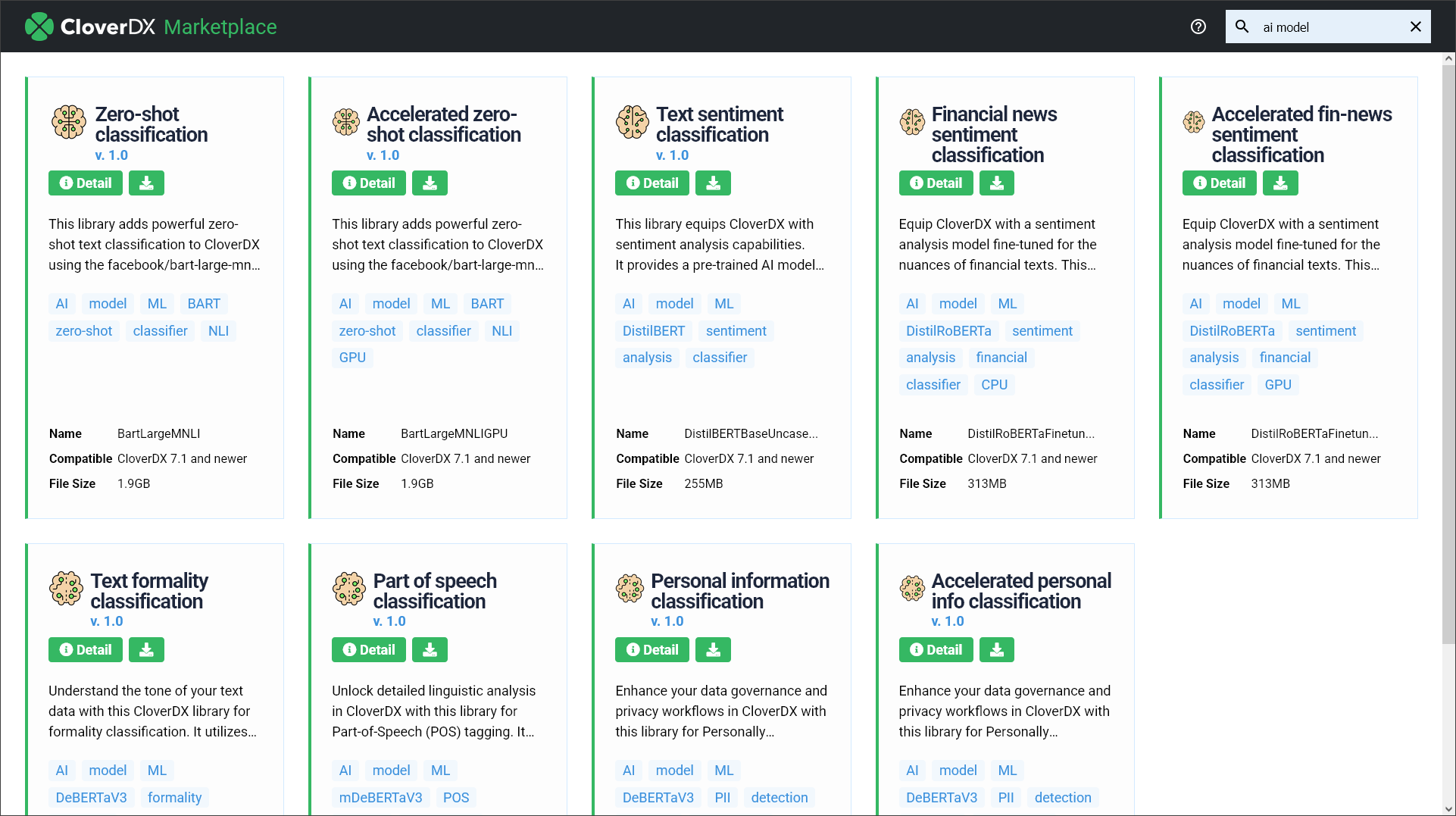
These libraries can all be installed via Libraries module in CloverDX Server. Once installed, the models are automatically enabled on the Server. You can then view their properties in the new AI / ML module.
To use the models you’ve installed, you can then simply select which model to use in your AI component in Designer.
Sharing Data Manager across multiple environments
Since the introduction of the Data Manager in CloverDX 7.0 you can easily create and manage data sets within a single CloverDX environment.
With CloverDX 7.1 we are introducing the ability for multiple CloverDX Servers (or clusters) to share a single Data Manager instance. This allows you to centralize all your data sets in a single location and use them across multiple CloverDX environments.
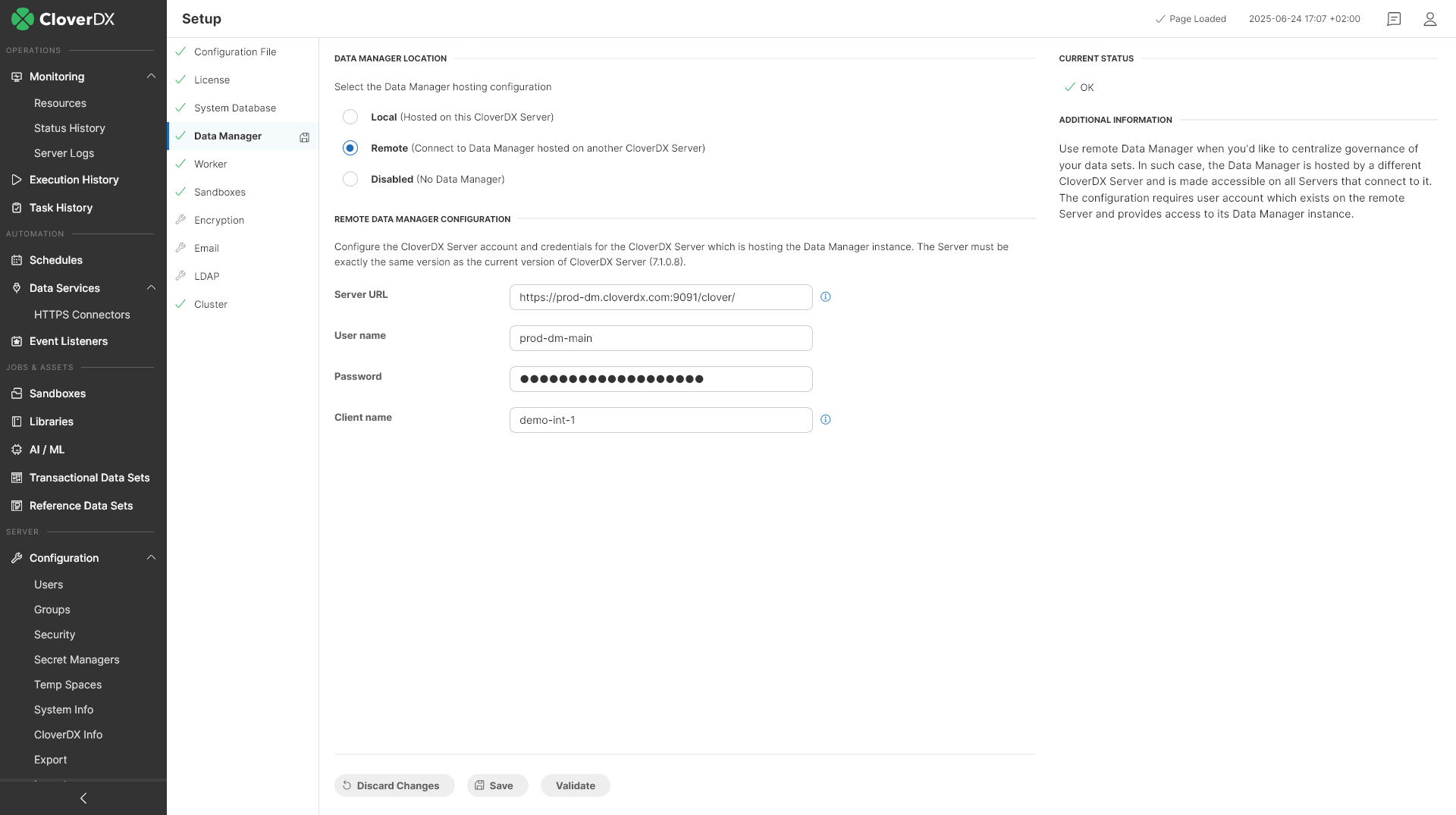
This approach offers multiple benefits like easier data governance as well as more predictable performance since you can pool all your interactive users of CloverDX Business Tools on a single machine and leave your automation running on different instances. This can then ensure that automated processes that may adhere to strict SLAs are not influenced by users working in Wrangler or in Data Manager.
Working with reference data in Wrangler
You can now easily work with reference data sets in your Wrangler jobs – whether you need to access your reference data as lookup or insert data into your reference data set.
All reference data sets now appear in the Data Catalog. Each data set can be accessed with two different connectors – one source and one target.
Reference data set sources allow you to use reference data sets whenever you need to read from it – typically when the data set is used as a lookup table in Wrangler job. This way you can very easily use shared reference data instead of having to define your own lookups via files uploaded to your Wrangler workspace.
Similarly, if you’d like to update your reference data set, you can use the target to do this. The target will add or update the records in the data set. Interactive users will then have to approve the changes in the Data Manager. This approach guarantees that the changes are not applied silently and that your data owners still retain full control over what is published in reference data sets.
Additional improvements
Descriptions for Listeners and Schedulers
We’ve added the ability to add descriptions to your Event Listeners and Schedulers. This will help you navigate more complex environments where you may have dozens or even hundreds of Listeners or Scheduler entries. Search in both modules searches within the description field so you can find what you are looking for faster.
At the same time, we are also providing more information about when the given entity was created or updated and who made the change.
Public REST API for Data Manager
We’ve introduced a read-only version of the Data Manager’s public API. IN this version, you can use the API to query information about your transactional and reference data sets as well as query the data in the data sets.
More complete API with the ability to write or modify data sets will be coming in CloverDX 7.2.
Platform support
DB2 no longer supported as Server system database
Starting with this release, IBM DB2 is no longer supported as the database that is used by the Server as its system / backend database. If you are using DB2, you will have to migrate to a different database – PostgreSQL, MySQL, Microsoft SQL Server, or Oracle. Consult our System requirements section in the documentation for more details.
Please note that this does not affect the ability to connect to DB2 databases from your graphs – this remains without any change.
To help you install or upgrade to this version, we've prepared a simple checklist:
Before you upgrade
- Be sure to check the "Compatibility" notes for ALL intermediary releases. We mark all changes that can potentially alter the function of your existing transformations with a "Compatibility" label. Typically, you can safely ignore most of them, as we try hard to keep as much backwards compatibility as possible. There's a comprehensive list of all releases that will help you get the information quickly.
- Upgrade Designer and Server together. We always release Designer and Server together under a single version. It's highly recommended to upgrade Server and all Designers at the same time. Although using different versions of Designer to connect to Server might work, it is not generally supported.
- There are no incremental patches. We don't release incremental patches. Every upgrade is in fact a full installation that, if installed over the older version, will automatically update whatever is necessary in your workspaces, sandboxes, and Server databases as needed, no user data will get overwritten.
- Don't forget to backup. Although none of the above upgrade steps requires explicit backup, we recommend you always back up your work. The upgrade will keep all your transformations, jobflows, and configurations safe. However, as a good word of advice, it never hurts to have a backup.
Designer upgrade
- Download the latest version by logging into your customer account. If you lost your credentials or no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Install the new version of Designer. You can install Designer over your existing installation. The process will automatically clean up the old version. Don't worry, you will NOT lose your workspaces, graphs, and transformations. However, if you installed some additional plugins to Designer (Eclipse plugins) you might need to reinstall them. Eclipse should automatically help you do that. When you start the application, point it to your existing workspace directory. With some major releases, we may notify you about upgrading the workspace to the latest version. In such cases, you won't be able to use the workspace with previous versions—be sure to upgrade ALL Designers at once if you're sharing the workspace.
- Activate the product on first start. You will need a new key as we issue new license keys for every new major version (e.g. from 4.9 to 5.0). If you're on our maintenance program, we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license keys from there. If you can't find the latest keys, please contact us to renew your product maintenance.
Server upgrade:
- Download the latest version by logging into your customer account. You'll find Server in the same list as Designer downloads. If you no longer have access there, click here to recover your password or contact our CloverCARE Support.
- Plan for downtime. Upgrading Server requires downtime, so plan your upgrades in advance. If you're running multiple environments, upgrade the non-production installation first and run all your tests there first.
- Follow our step-by-step Server Upgrade Guide. We've prepared detailed instructions on how to properly shut down Server and install a new one. Server will upgrade its database and sandboxes from any previous version automatically.
- Activate the product on the login screen of Server Console. Server requires new license keys with every minor version (e.g. from 4.9 to 5.0) and we automatically renew the keys for you. Just go to the License Keys again and copy/paste the license key from there.
Please consult our Upgrading to CloverDX Server 7.0 article for additional details with more detailed overview of how to upgrade from Apache Tomcat 9 to Apache Tomcat 10.1.
| Release | Compatibility/Upgrade notes, Features & Fixes | Published | Download | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
AI/ML Support
Business Tools
Security
Fixes
Miscellaneous
Compatibility
|
June 24, 2025 | Documentation Download CloverDX 7.1 7.1.0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- For Developers (Improvements most useful for developers bringing new functionality or optimizations in data transformation and orchestration)
- For Administrators (Improvements or features that will help setup, install, administer and manage the platform)
- For Support (Helps staff supporting the production environment to identify and escalate potential problems or avoid such)
- For Security (Improvements and changes relevant to security focused staff – sys admins and developers alike)